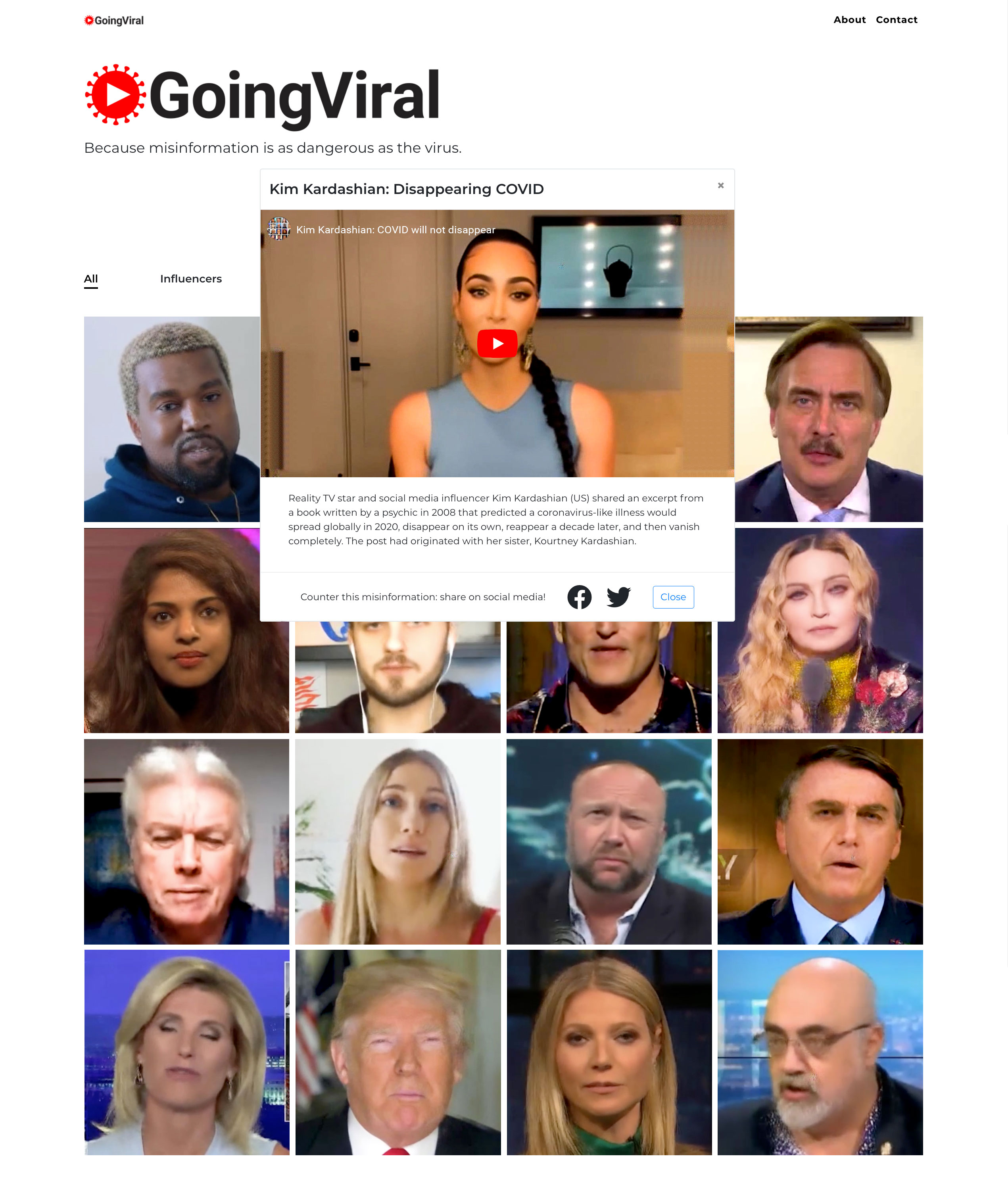
Going Viral is an interactive artwork that invites people to intervene in the spreading of misinformation by sharing informational videos about COVID-19 that feature algorithmically generated celebrities, social media influencers, and politicians that have previously shared misinformation about coronavirus. In the videos, the influencers deliver public service announcements or present news stories that counter the misinformation they have promoted on social media.
The videos in Going Viral are made using a Pix2Pix conditional generative adversarial network (cGAN). In a cGAN, a neural network is trained on sets of two images where one image becomes a map to produce a second image. In Going Viral, the two images are landmarks from facial recognition and a frame from a video. Once the model is trained, it can be used to generate an image of a face based on only the facial landmarks from the first image.
This work is a collaboration with Jennifer Gradecki, and was made possible in part by the generous support of NEoN Digital Art Festival.
Click here to visit the project site









New video is generated from the facial landmarks of the input speaker.
The videos in Going Viral are made using a Pix2Pix conditional generative adversarial network (cGAN). In a cGAN, a neural network is trained on sets of two images where one image becomes a map to produce a second image. In Going Viral, the two images are landmarks from facial recognition and a frame from a video. Once the model is trained, it can be used to generate an image of a face based on only the facial landmarks from the first image.
The process starts by extracting the facial landmarks of an influencer, celebrity, or politician from frames of a video. A model that maps the landmarks to a specific image of the influencer is then trained. Next, we take video of an expert or journalist speaking on a topic the influencer has spread misinformation about and extract the facial landmarks from that expert. We then use the facial landmarks of the second speaker to generate video frames of influencer, celebrity, or politician speaking the same words. Finally, the new frames are combined with the audio track of the expert or journalist to produce a new video where an influencer is correcting the misinformation they have spread.